ABB’s application-specific Variable Speed Drives (VSDs) are dynamic and energy efficient.
Have you ever had a problem with variable speed drives (VSDs) tripping residual current devices (RCDs) on the supply side of the VSD?
The cause of VSDs occasionally tripping RCDs is because they have an EMC ( Electromagnetic Compatibility) filter, also known as an RFI(Radio Frequency Interference) filter. Compatibility) filter, also known as an RFI(Radio Frequency Interference) filter.
These filters' purpose is to attenuate high-frequency emissions generated by the VSD to earth, preventing them from being conducted back down the supply cables.
The EMC filter attenuates high-frequency emissions from the VSD to earth via capacitors, resulting in some leakage current to earth. The amount of leakage current is determined by the type of EMC filter used as well as the number of amps required by the load supplied by the VSD.
The amount of current flowing to earth increases as the load increases, which can cause an RCD to trip. There are several solutions, three of which we have outlined.
- Remove the EMC filter, which is simple to do on most ABB VSDs by removing or backing off a couple of screws. Disconnecting the EMC filter has the disadvantage of causing other sensitive electronic equipment in close proximity to the VSD to function improperly due to EMC interference.
- As previously suggested, disconnect the drive's internal EMC filter, but then connect an external low leakage EMC filter in series with the drive's input.
- Replace the RCD with one with a higher trip threshold, but make sure the RCD trip threshold still protects personnel.
When opting for an RCD, the thresholds determined have been incorporated into modern standards shown graphically in the below figure from IEC 60479-1:2018. This time-current graph shows human sensitivity to AC currents broken down into 4 main zones.
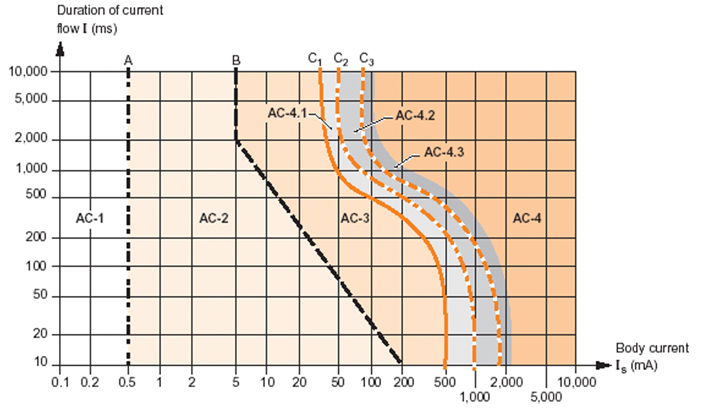
- AC-1: Perception possible but usually no startled reaction
- AC-2: Involuntary muscular contraction but no harmful effects
- AC-3: Strong muscular contractions, reversible disturbance to heart function, and difficulty breathing.
- AC-4: Possible irreversible effects (i.e. burns) and risk of ventricular fibrillation
AC-4.1 <5% chance of heart fibrillation
AC-4.2 <50% chance of heart fibrillation
AC-4.3 >50% chance of heart fibrillation
To determine the trip threshold, we can see from the graph that a trip threshold of 30mA means that the shock current, regardless of duration, will never enter the zone where it could cause heart fibrillation. By limiting the maximum trip time at 30mA to 300ms, the actual tripping threshold is kept below a level that causes problems with breathing or the heart. Similarly, a current of 5xIDn (150mA) must cause a trip in less than 40ms. This is why the trip thresholds have been set at the levels they have.
If you’d like to learn more about RCD technology or standards, please click here and browse our range of Variable Speed Drives, please click here.
|